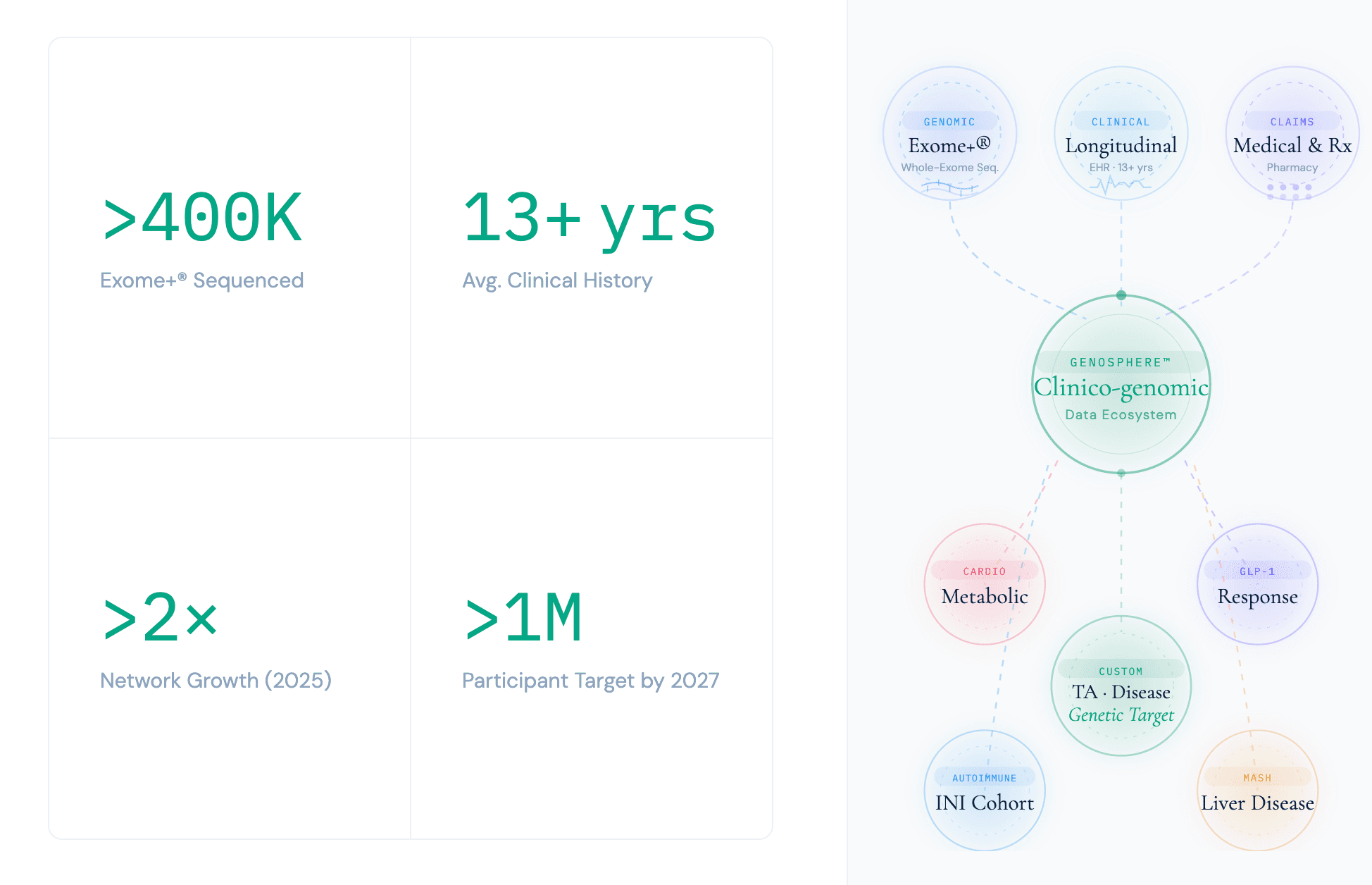
Key Highlights
- GenoSphere™ is Helix's centralized clinico-genomic research data ecosystem — with specialized cohorts that combine whole Exome+® sequencing data linked to an average of 13 years of longitudinal EHR and claims data across 400,000+ consented participants.
- Specialized GenoSphere cohorts including Cardiometabolic grew +102% YoY to 230K+ participants; GLP-1 grew to 55K+ participants; Autoimmune/INI grew to 48K+ participants - overall cohort more than doubled in 2025 indicating significant growth across all targeted areas
- GenoSphere is one of the world’s largest specialized GLP-1 clinico-genomic dataset with >55K participants being administered GLP-1 agonists including semaglutide and tirzepatide for treatment of diabetes, obesity and other related conditions.
- All participants are consented for recontact, making the dataset suitable not just for observational research but also for clinical trial recruitment, targeted follow-up studies, and prospective phenotyping.
What makes GenoSphere different from a typical EHR biobank or claims-only database?
Simply put, it's the combination and in-depth curation. Researchers get deep genomic data paired with deep clinical histories — an average of 13+ years of longitudinal EHR per participant, enriched with medical and pharmacy claims data, all harmonized to the OMOP standard. And because every participant has consented to recontact, these aren't just records — they're people who can be engaged for clinical trials, surveys, and follow-up research.
The dataset now spans more than 400,000 whole-genome sequenced individuals with linked clinical data, — and we're on track toward a goal of enrolling 1 million participants by 2027.
GenoSphere Cohorts More Than Doubled in 2025 — Here's the Data
Looking at where GenoSphere started in Q1 2025 versus where it stands today, the growth across every therapeutic area has been remarkable — our Cardiometabolic, GLP-1, and Autoimmune/INI cohorts more than doubled over the course of the year.
- Cardiometabolic cohort grew to >230K records (114K in Q1) with a 102% YoY growth rate
- GLP-1 specialized cohort is now at >55K records (18K in Q1) with a 197% YoY growth rate
- Autoimmune/INI cohort increased to >48K records (23K in Q1) with a 104% YoY growth rate
That's not incremental progress — that's a fundamentally different dataset. Here's a closer look at each.
What is the breadth of data that researchers are getting with the GenoSphere Cardiometabolic Cohort ?
The GenoSphere cardiometabolic cohort is our largest and most established, covering individuals with a broad range of cardiovascular and metabolic conditions.
- >230,000 genomically sequenced participants (up nearly 22% from Q3 alone). Year-over-year, the HRN cohort has more than doubled — crossing the 200K milestone in 2025 and showing no signs of slowing down.
- Conditions include coronary artery disease, heart failure, hypertension, type 2 diabetes, dyslipidemia, and chronic kidney disease.
One area that stands out within cardiometabolic research is lipid-related disease. Helix recently published findings examining population genomic screening and improved lipid management in patients with Familial Hypercholesterolemia — a genetically-driven condition that dramatically increases cardiovascular risk but often goes undiagnosed. The scale of the GenoSphere cardiometabolic cohort is exactly what makes this kind of research possible at a population level.
How GenoSphere Has the World's Largest Specialized GLP-1 Clinicogenomic Cohort
Few drug classes have moved faster in the clinic than GLP-1 receptor agonists for the treatment of a wide range of cardiometabolic and other diseases. The GenoSphere GLP-1 cohort includes:
- >55,000 individuals being administered GLP-1 agonists including Semaglutide and Tirzepatide - with linked genomic profiles and longitudinal clinical data
So what can you do with this dataset? A lot. Researchers at Helix recently demonstrated one answer with our GLP-1 Precision Effectiveness Model, which combines a polygenic risk score (PRS) for BMI with clinical factors like diabetes and hypertension to inform HCP consideration of individual treatment response to semaglutide.
- The outcome: Patients with a high predicted likelihood of response were nearly twice as likely to achieve ≥10% weight loss compared to those with a low predicted likelihood (67% vs. 36%).
How GenoSphere Is Addressing the Scale Problem in Autoimmune Research
Immune-mediated diseases are notoriously difficult to study — heterogeneous presentations, variable treatment responses, and complex gene-environment interactions. Scale and longitudinal depth matter enormously here. The GenoSphere Inflammatory and Immune (INI) cohort includes:
- >48,000 individuals — up 20% from Q3 and more than double the Q1 2025 baseline.
- Covers a broad range of immune-mediated conditions including Lupus (SLE), Rheumatoid Arthritis, Inflammatory Bowel Disease (IBD), and more.
Having this breadth within a single genetically characterized, longitudinally tracked cohort enables cross-disease genetic analysis, biomarker discovery, and comparative effectiveness research that simply isn't feasible with smaller, siloed datasets.
What Makes the GenoSphere MASH Data Uniquely Actionable for Researchers
The MASH cohort consists of records for metabolic dysfunction-associated steatohepatitis (MASH) — a severe inflammatory form of fatty liver disease that affects an estimated 22 million Americans. The cohort is broken down into high-risk and affected populations, giving a clearer picture of disease severity and a more actionable dataset for researchers targeting this challenging space:
- ~20,000 High-Risk records — with FIB-4 scores above 2.67, associated with advanced/severe liver fibrosis
- ~2,500 MASH-affected records depending for diagnosed individuals
More than 90% of the cohort carries FIB-4 scores consistent with severe fibrosis, and over 70% have BMI classified as overweight or obese — reflecting the well-established link between MASH and metabolic syndrome. With longitudinal lab data spanning years, researchers can track disease trajectory and treatment response over time rather than relying on a single clinical encounter.
How Can Life Sciences Teams Work with GenoSphere in 2026?
The growth in GenoSphere's cohorts over 2025 reflects both the expanding Helix network and the increasing demand from life sciences partners for high-quality, research-ready clinico-genomic data. Every quarter, new participants are added, clinical data is refreshed, and customized cohorts can be built through our Helix digital cohort builder.
If you're working in precision medicine, drug discovery, or outcomes research, we'd love to connect. Whether it's exploring a specific cohort, designing a study, or discussing how GenoSphere data can accelerate your pipeline — our translational research team is ready.
Common Questions You May Have
Does GenoSphere only cover certain therapeutic areas?
While GenoSphere includes curated specialized cohorts in cardiometabolic disease, GLP-1 receptor agonist research autoimmune and inflammatory conditions and MASH, Helix can always curate a specific cohort from the therapeutic area level to the specific genetic target of interest. You can also build customized cohorts using the Digital cohort builder.
Can GenoSphere data be used to support clinical trials?
Yes. Because every GenoSphere participant has consented to recontact, the dataset supports not only observational research but also targeted recall, clinical trial recruitment, and prospective follow-up studies through Helix's Recall-by-Genotype (RbG) capability — enabling researchers to identify genetically eligible participants before a single screening visit.
How does GenoSphere align to compliance and privacy standards?
GenoSphere data is collected from consented participants, in accordance with IRB approved research protocols, and handled in accordance with applicable research regulations and privacy frameworks. Research datasets are de-identified in accordance with HIPAA’s Expert Determination Method and harmonized to the OMOP Common Data Model to support collaborative research. Helix operates CLIA- and CAP-accredited laboratories and maintains rigorous data governance standards across its research network.
How does a life sciences team get started with GenoSphere?
Most engagements begin with a feasibility assessment — researchers define their target population (by genotype, phenotype, or both), and Helix queries GenoSphere to estimate cohort size and stratification options. From there, teams can move into data access, custom cohort development, or a full Recall-by-Genotype protocol depending on study objectives. Helix's translational research team works directly with partners to scope and design engagements.